Basic Artificial Intelligence interview questions and answers

Table of Contents:
- Explain Artificial Intelligence
- How are machine learning and AI related?
- What is Deep Learning based on?
- How many layers are in a Neural Network?
- Explain TensorFlow
- Difference between NLP and NLU
- Examples of weak and strong AI
- What is Artificial Narrow Intelligence (ANI)?
- What is a data cube?
- Components of GAN
- Common data structures used in deep learning
- Advantages of neural networks
- Difference between stemming and lemmatization
- What is the meaning of corpus in NLP?
- Explain binarizing of data
- Explain marginalization process
- How are speech recognition and video recognition different?
Artificial Intelligence (AI) has quickly become an essential part of modern technology. It affects many industries, like healthcare and finance. As AI grows, it’s important to understand its basic concepts and how it’s used.
This knowledge is valuable for anyone looking to enter the AI field or prepare for interviews. Basic AI interview questions usually cover topics such as machine learning, neural networks, and cognitive computing.
These questions check if you understand how AI systems work, the technologies behind them, and how they solve real-world problems.
When preparing for AI interviews, you should not only know the theory but also understand how AI works in practice. Be ready to explain how deep learning frameworks build complex models, how speech and video recognition are different, and how marginalization works in probability models.
Understanding these basics will help you discuss both the overall concepts and the technical details of AI. This will show that you are ready for jobs where you design, implement, or manage AI solutions.
Are you interested in learning about AI? Join our free demo at CRS Info Solutions to interact with our expert instructors and discover how our job-oriented AI online course can benefit you. With real-time project-based learning, daily notes, and interview preparation materials, you’ll gain the practical knowledge needed to excel in the field. Don’t miss out—enroll now for your free demo and start your AI journey today!
1. Explain Artificial Intelligence and give its applications.
AI, or Artificial Intelligence, is a part of computer science. It focuses on building machines that can perform tasks requiring human intelligence. These tasks include problem-solving, decision-making, understanding language, and recognizing patterns. AI uses algorithms, data, and computing power to learn from its environment. It improves over time without needing instructions. In simple words, AI behaves like a human brain, helping machines solve complex problems.
AI is used in many industries. For example:
- Healthcare: Diagnosing diseases with medical images and predicting patient outcomes.
- Finance: Detecting fraud, managing trading, and helping with personal finances.
- Customer service: Using chatbots and virtual assistants to improve customer support.
Other uses include self-driving cars, personalized content recommendations, and automating business processes.
Explore: Data Science Interview Questions
2. How are machine learning and AI related?
Machine learning (ML) is a part of Artificial Intelligence (AI). It focuses on teaching machines to learn from data.
AI is about making machines that can think and make decisions. Machine learning, however, is about using techniques and algorithms. These help machines find patterns in data without needing human help.
In machine learning, systems are trained with large amounts of data. They use this data to make predictions or decisions. For example, machine learning helps email systems decide if an email is spam or not spam based on past user actions.
AI can do more than just learn. It can also reason, understand, and interact with the environment. For example, robots or systems that understand human language.
So, machine learning is a part of AI, but AI includes more technologies. Some AI systems follow rules or act like experts without learning from data.
Are you interested in learning about AI? Join our free demo at CRS Info Solutions to interact with our expert instructors and discover how our job-oriented AI online course can benefit you. With real-time project-based learning, daily notes, and interview preparation materials, you’ll gain the practical knowledge needed to excel in the field. Don’t miss out—enroll now for your free demo and start your AI journey today!
3. What is Deep Learning based on?
Deep learning is based on artificial neural networks. These networks are inspired by how the human brain works.
In deep learning, there are many layers of connected nodes or neurons. These layers process and change input data into useful information. This is why it’s called “deep” learning.
These layers help the model learn on its own from the data. This lets it do tasks like recognizing images, translating languages, or understanding speech. Each layer turns the data into a more detailed form, helping the system spot even very complex patterns.
Deep learning uses algorithms like backpropagation. This helps adjust the network to reduce mistakes in predictions. The network keeps learning and improving over time.
For example, in image classification, a special deep learning model called a Convolutional Neural Network (CNN) is used. It has layers that filter image data to find features like edges, textures, or objects.
Deep learning needs a lot of data and strong computers. But it has been very successful in AI, especially in areas like computer vision (making machines “see”) and understanding human language.
Read more: Data Science Interview Questions Faang
4. How many layers are in a Neural Network?
A neural network typically consists of three main types of layers: the input layer, one or more hidden layers, and the output layer. The input layer is responsible for receiving the data in its raw form, such as images, text, or numerical values. The hidden layers, which may range from one to several (especially in deep neural networks), process this input data by applying a series of mathematical transformations and passing the results to the next layer.
Each hidden layer refines the data, allowing the network to recognize more intricate patterns. The output layer produces the final result, which could be a classification, a prediction, or some other actionable output.
The number of hidden layers in a neural network often defines its complexity. In simple tasks like linear regression, one hidden layer may suffice, while more complex problems, like image classification or language translation, may require deep networks with many hidden layers. Below is a simple structure of a neural network using Python’s Keras library to demonstrate this:
import Sequential
from keras.layers import Dense
# Define a simple neural network with one input layer, two hidden layers, and one output layer
model = Sequential()
model.add(Dense(64, input_dim=10, activation='relu')) # Input layer
model.add(Dense(32, activation='relu')) # First hidden layer
model.add(Dense(16, activation='relu')) # Second hidden layer
model.add(Dense(1, activation='sigmoid')) # Output layer
In this code, I am creating a sequential model with one input layer (receiving 10 features), two hidden layers (with 64 and 32 neurons respectively), and an output layer that returns a single output. This kind of structure is common in many classification and prediction tasks.
Read more: Google Data Scientist Interview Questions
5. Explain TensorFlow.
TensorFlow is an open-source library for machine learning and deep learning. It was created by Google. Developers use TensorFlow to build and train neural networks. It helps them create complex machine learning models easily.
One great feature of TensorFlow is that it can run on both CPUs and GPUs. This means it can handle large projects and is scalable. TensorFlow uses data flow graphs to do calculations. In these graphs, nodes are like math operations, and edges are data moving between them.
TensorFlow is very flexible. It supports many different machine learning algorithms. Developers can use low-level APIs to control every part of the model or high-level APIs like Keras to build models faster.
TensorFlow has a strong community and works with other tools like TensorBoard. TensorBoard helps you see how your model is learning, which is useful in AI projects.
Cognitive Computing
Cognitive computing means using technology that acts like the human brain to solve complex problems. It processes and analyzes large amounts of data in real-time. Unlike regular computers that follow fixed rules, cognitive systems can learn, adapt, and offer insights.
This technology is useful in areas like healthcare, finance, and customer service. It helps make better decisions by understanding huge amounts of different data.
One major benefit is that cognitive computing improves human decision-making. It finds important insights that people might miss. For example, in healthcare, systems like IBM Watson read patient records, medical studies, and trials to suggest personalized treatments.
Another benefit is that cognitive computing can automate repetitive tasks. This makes work faster, reduces mistakes, and helps businesses be more efficient.
7. What’s the difference between NLP and NLU?
Natural Language Processing (NLP) and Natural Language Understanding (NLU) are two related areas, but they have different roles.
NLP involves a wide range of techniques to handle human language. It covers tasks like speech recognition, language translation, and summarizing text. NLP mainly focuses on changing unstructured language into a form that machines can read and work with. It deals with syntax (the grammar and structure) and semantics (the meaning). This helps machines work with many different language tasks.
NLU, however, is a part of NLP. It specifically focuses on understanding the meaning behind the language. While NLP organizes and processes language, NLU finds the meaning, context, and intent in the text.
For example, in a virtual assistant, NLP converts spoken language into text. Then, NLU figures out what the user wants, like booking a flight or setting a reminder. In simple terms, NLP is about processing language, and NLU is about understanding it.
8. Give some examples of weak and strong AI.
Weak AI, also known as narrow AI, is designed to perform a specific task. It operates under a limited scope and does not possess general intelligence. Examples of weak AI include virtual assistants like Siri and Alexa, which can respond to voice commands but are limited to the tasks they are programmed for.
Another example is chatbots used in customer service, which can answer frequently asked questions but cannot engage in general conversation. Weak AI excels in specific areas but does not have the capability to think or reason beyond its defined parameters.
Strong AI, also referred to as artificial general intelligence (AGI), aims to replicate human cognitive abilities across a wide range of tasks. Strong AI would have the ability to reason, plan, learn, and understand abstract concepts just like humans. While strong AI remains a theoretical concept today, it represents the ultimate goal of AI research.
In theory, AGI could perform any intellectual task a human can, such as solving complex problems, creating art, and making ethical decisions. However, achieving strong AI is still a long way off, as we are currently far from creating machines with this level of autonomy and reasoning power.
9. What is the need of data mining?
Data mining is crucial in today’s data-driven world because it helps organizations make sense of the vast amount of data they collect. With the exponential growth of data, it’s nearly impossible for humans to manually analyze and extract useful information from it.
Data mining enables organizations to uncover hidden patterns, trends, and correlations in large datasets, which can then be used for better decision-making. For instance, data mining techniques are commonly used in market basket analysis to understand consumer behavior and optimize product placement in stores.
The need for data mining extends to various industries. In finance, data mining helps detect fraud by identifying unusual patterns in transaction data.
In healthcare, it can be used to predict disease outbreaks by analyzing patient data and environmental factors. Retail companies use data mining to personalize recommendations and improve customer retention. In essence, data mining allows businesses to turn raw data into actionable insights, helping them stay competitive in their respective markets.
10. Name some sectors where data mining is applicable.
Data mining is used in many different fields. It helps find useful patterns and trends from large datasets.
In the finance sector, data mining is used for credit scoring, fraud detection, and risk management. It helps banks study customer data to see who is likely to repay loans or to spot unusual transactions.
In healthcare, data mining helps track patient trends. It improves diagnoses and helps create better treatment plans by studying past patient data.
The retail industry uses data mining to understand customer behavior. It helps create personalized marketing campaigns and manage product inventory. Online stores (e-commerce) use data mining to suggest products based on what customers browsed or bought before.
In telecommunications, data mining helps companies keep their customers by spotting patterns in complaints and usage data.
Other fields like education, manufacturing, and insurance also use data mining. It helps them make better decisions and improve their processes with predictive models.
11. What are the components of NLP?
Natural Language Processing (NLP) has several important parts that help machines understand human language.
One key part is tokenization. This means breaking down text into smaller units, like words or sentences. It helps the system understand each part of the text. For example, in sentiment analysis, tokenization helps break a customer review into words, making it easier to figure out if the review is positive or negative.
Another part is morphological analysis. This means understanding the structure of words, like prefixes, suffixes, and root words.
Part-of-speech (POS) tagging is also very important. It labels each word with its grammatical category (like noun, verb, or adjective). This helps the system understand how words fit together in a sentence.
Another key part is Named Entity Recognition (NER). This finds and labels important names in the text, such as people, places, or organizations. NER is useful in things like chatbots and search engines to pick out the information users are looking for.
These parts work together to help NLP systems process and understand language in a clear and organized way.
12. What is the full form of LSTM?
LSTM stands for Long Short-Term Memory, which is a type of recurrent neural network (RNN). LSTM networks are designed to remember information over long periods and are particularly useful for tasks that involve sequential data, such as time series forecasting, natural language processing, and speech recognition. Unlike traditional RNNs, which struggle with long-term dependencies due to the vanishing gradient problem, LSTMs use memory cells and gates to retain and control the flow of information over time. These gates help determine which information to keep, update, or discard, making LSTMs effective at handling complex, time-dependent tasks.
LSTMs have become particularly popular in language modeling tasks, such as machine translation and text generation. For instance, when translating a sentence from English to Spanish, an LSTM can remember the context of the entire sentence, ensuring that words are translated accurately and maintain their meaning. LSTM networks are also widely used in speech recognition applications, where the ability to understand and predict the next word in a sequence is crucial for generating accurate transcriptions.
13. What is Artificial Narrow Intelligence (ANI)?
Artificial Narrow Intelligence (ANI), also known as weak AI, refers to AI systems that are designed and trained for a specific task or domain. ANI is limited to performing one particular task extremely well but lacks the ability to generalize knowledge or apply its learning to different tasks. For example, a chess-playing AI like AlphaZero is an example of ANI—it excels at playing chess but cannot perform other unrelated tasks like driving a car or diagnosing medical conditions. ANI is the most common form of AI used today in applications such as voice assistants, recommendation systems, and fraud detection algorithms.
The key feature of ANI is its narrow scope of operation. While ANI systems can often outperform humans in specific tasks, such as facial recognition or pattern matching, they do not possess the general intelligence required to perform tasks outside of their predefined scope. This contrasts with Artificial General Intelligence (AGI), which would theoretically be able to learn and perform any intellectual task a human can do. ANI is ubiquitous in modern AI applications but remains limited by its narrow focus.
14. What is a data cube?
A data cube is a multidimensional array of values, commonly used in data warehousing and OLAP (Online Analytical Processing) systems. Data cubes allow for the representation of data along multiple dimensions, such as time, product, region, and other attributes. The structure of a data cube enables users to quickly perform complex queries, such as slicing, dicing, and aggregating data across different dimensions. For instance, a business analyst can use a data cube to analyze sales data by time (e.g., month), product (e.g., electronics), and location (e.g., North America) simultaneously.
Data cubes are particularly useful for multidimensional analysis, where large volumes of data need to be aggregated and summarized across various factors. The dimensions of a data cube typically represent categories of interest, while the data values within the cube are the measures being analyzed, such as sales figures or revenue.
Operations such as slicing, which refers to extracting a specific subset of data (e.g., sales for Q1), and dicing, which selects a more granular view (e.g., sales for Q1 in the electronics category), are common when working with data cubes. This structure provides an efficient way to query and analyze large datasets in business intelligence applications.
15. What is the difference between model accuracy and model performance?
Model accuracy refers to the percentage of correct predictions made by a model compared to the total predictions. It is one of the most commonly used metrics for evaluating classification models. For instance, if a model correctly predicts 90 out of 100 cases, its accuracy would be 90%. While accuracy is an important measure, it may not always reflect the true performance of a model, especially in imbalanced datasets where one class dominates the other. In such cases, even a high accuracy score could be misleading, as the model may be overfitting to the majority class while ignoring the minority class.
Model performance, on the other hand, encompasses a broader range of evaluation metrics, such as precision, recall, F1-score, and AUC-ROC. These metrics provide a more comprehensive understanding of how well a model performs, especially when dealing with imbalanced datasets.
For example, in a medical diagnosis model, precision and recall might be more important than accuracy, as they measure how well the model identifies true positive cases without raising too many false alarms. In addition to classification metrics, performance can also be evaluated through measures like mean squared error (MSE) or R-squared for regression models.
Therefore, while accuracy is a useful metric, model performance offers a deeper insight into the model’s strengths and weaknesses.
16. What are different components of GAN?
Generative Adversarial Networks (GANs) consist of two main components: the generator and the discriminator. These two neural networks are pitted against each other in a competitive setting. The generator’s job is to create synthetic data that resembles the real data, such as images or text, while the discriminator’s task is to distinguish between real and fake data.
This adversarial process continues until the generator gets better at creating realistic data, and the discriminator improves at identifying fake data. Over time, the generator learns to create data that the discriminator finds indistinguishable from the real data.
The key innovation in GANs is this adversarial training mechanism, where both networks are trained simultaneously but have opposing objectives.
For example, in image generation tasks, the generator network might use random noise as input and attempt to generate realistic images. The discriminator, on the other hand, evaluates both the real images from the dataset and the fake images from the generator, classifying them as real or fake.
The generator aims to “fool” the discriminator, while the discriminator strives to become more accurate at detecting fakes. This dynamic leads to highly realistic synthetic data.
17. What are common data structures used in deep learning?
In deep learning, various data structures are used to organize and process data efficiently. One of the most common data structures is the tensor, which is a generalization of matrices and vectors. Tensors can represent data in multiple dimensions, making them ideal for deep learning models, where data such as images, videos, and time series often have several dimensions (e.g., height, width, depth, and time). Deep learning frameworks like TensorFlow and PyTorch rely heavily on tensors to feed data into neural networks and perform computations during model training.
Another commonly used data structure is the graph, especially in frameworks like TensorFlow. Graphs represent the computations in a deep learning model, where nodes represent operations, and edges represent the flow of data (or tensors) between these operations. These computational graphs enable efficient execution and parallelization across different computing units like CPUs and GPUs. Additionally, queues and stacks may be used for storing data points during the model’s training or evaluation phase, helping manage large datasets in a more structured way.
18. What is the role of the hidden layer in a neural network?
The hidden layers in a neural network are crucial for capturing the complexity of the data. Each hidden layer is responsible for performing non-linear transformations on the input data, allowing the network to learn more abstract and high-level features as the data progresses through the layers. In a simple feedforward neural network, the input layer passes raw data into the first hidden layer, where each neuron applies a set of weights and biases to the data, followed by a non-linear activation function. The processed data is then passed to subsequent hidden layers, allowing the model to capture deeper patterns.
Hidden layers are particularly important in deep learning models, where multiple layers enable the model to learn hierarchical representations of the data. For instance, in an image recognition task, the first hidden layer might detect simple features like edges, while deeper hidden layers may recognize more complex structures like shapes and objects. The output from the final hidden layer is passed to the output layer, which makes the final prediction or classification. Thus, the hidden layers serve as the engine of a neural network, extracting meaningful features that are not immediately apparent from the raw input data.
19. Mention some advantages of neural networks.
Neural networks offer several advantages, making them widely used in a variety of AI and machine learning applications. One of their primary advantages is their ability to handle complex and non-linear data. Unlike traditional algorithms that may struggle with non-linear relationships, neural networks can model and approximate almost any function by learning from the data. This makes them particularly useful in applications like image recognition, natural language processing, and speech recognition, where the data is often unstructured and highly complex.
Another advantage of neural networks is their ability to generalize from the data, meaning they can make accurate predictions on unseen data once trained properly. They can automatically learn and extract features from the raw data without needing extensive manual feature engineering. Additionally, neural networks are scalable, allowing them to handle vast amounts of data and complex models. Modern architectures like convolutional neural networks (CNNs) and recurrent neural networks (RNNs) are optimized for specific tasks, such as image and sequence-based data, enhancing their efficiency and accuracy.
20. What is the difference between stemming and lemmatization?
Stemming and lemmatization are both techniques used in natural language processing (NLP) to reduce words to their root forms, but they differ in their approach. Stemming is a rule-based process that removes prefixes and suffixes to reduce a word to its base form, often leading to incomplete or incorrect root forms. For example, stemming would reduce the words “running,” “runs,” and “ran” to “run,” but sometimes the result might not be an actual word, such as reducing “studies” to “studi.”
Lemmatization, on the other hand, is more sophisticated. It uses morphological analysis to reduce words to their base form (lemma), taking into account the word’s meaning and part of speech. For instance, lemmatization would correctly identify “better” as the lemma of “good” and “studies” as the plural of “study,” rather than simply cutting off suffixes. While stemming is faster and simpler, lemmatization is more accurate and contextually aware, making it better suited for applications where the precise meaning of words matters, such as text classification or sentiment analysis. Here’s an example of lemmatization using Python’s NLTK library:
import WordNetLemmatizer
lemmatizer = WordNetLemmatizer()
print(lemmatizer.lemmatize("studies", pos="n")) # Output: study
print(lemmatizer.lemmatize("running", pos="v")) # Output: runIn this code, I am using the NLTK library to lemmatize the words “studies” and “running” based on their parts of speech (noun and verb, respectively), demonstrating how lemmatization returns the correct base forms.
21. What are the different types of text summarization?
Text summarization can be broadly classified into two types: extractive and abstractive summarization. Extractive summarization involves selecting key sentences, phrases, or portions directly from the source text and concatenating them to form a summary. It works by identifying the most important sections of the text and stringing them together without any modification. The quality of extractive summarization depends on the algorithm’s ability to recognize the core ideas in the text and accurately extract relevant information. Algorithms like TF-IDF (Term Frequency-Inverse Document Frequency) and TextRank are commonly used in extractive summarization techniques.
On the other hand, abstractive summarization generates a summary by understanding the context and rewriting the content in a new, concise form, often paraphrasing the text rather than just extracting it. This method is more complex as it requires the model to comprehend and interpret the text before generating a summary, often using techniques from natural language generation (NLG). Abstractive summarization tends to produce more human-like summaries but may introduce factual inaccuracies if the model misinterprets the content. Recent advancements in deep learning, particularly with transformer models like BART and T5, have made abstractive summarization more practical and widely used.
22. What is the meaning of corpus in NLP?
In Natural Language Processing (NLP), a corpus is a large and structured set of texts that serve as a foundation for training models and conducting linguistic analysis. It can consist of written or spoken text in any language and may vary in size, content, and structure depending on the task. For example, a news corpus might contain articles from different newspapers, while a speech corpus might include transcripts of conversations or interviews. The goal of using a corpus is to provide sufficient real-world language data for the machine learning algorithms to learn patterns, relationships, and semantics in natural language.
Corpora are essential in various NLP tasks, such as training language models, building text classification systems, or developing machine translation tools. Some well-known corpora include the British National Corpus (BNC), which consists of a wide range of British English texts, and COCA (Corpus of Contemporary American English), which is often used for American English language studies. By analyzing large corpora, models can develop better representations of language, improving their ability to perform tasks like language translation, sentiment analysis, and question-answering.
23. Explain binarizing of data.
Binarizing is the process of converting data into a binary format, which typically means converting it into two categories, often represented as 0 and 1. In machine learning, binarization is commonly applied to categorical features or data that can be logically divided into two groups. For instance, in text classification, binary vectors are used to represent the presence or absence of specific words in a document. Similarly, for a classification problem where the output could be “spam” or “not spam,” binarizing the labels involves assigning 1 to “spam” and 0 to “not spam.”
Binarization is also used in image processing to convert grayscale images to black and white. This helps simplify the model’s task by reducing the complexity of the input data. In scikit-learn, binarizing numeric data can be done using the Binarizer class, which converts feature values to either 0 or 1 based on a specified threshold. Here’s an example:
from sklearn.preprocessing
import Binarizer
# Create some sample data
data = [[1.5, 2.3, 0.7], [0.2, 3.8, 1.4]]
# Apply binarization with threshold 1.0
binarizer = Binarizer(threshold=1.0)
binarized_data = binarizer.transform(data)
print(binarized_data) # Output: [[1. 1. 0.], [0. 1. 1.]]In this example, I am binarizing the data based on a threshold of 1.0. Values greater than 1.0 are converted to 1, while values less than or equal to 1.0 are converted to 0.
24. What is perception and its types?
Perception in the context of artificial intelligence refers to the ability of machines to interpret and make sense of the input they receive from their environment, often mimicking how humans perceive the world. This is achieved through sensors, cameras, microphones, or other data-gathering devices that collect information. The AI system then processes this information to recognize patterns, objects, or events. For example, computer vision systems use perception to recognize objects in an image, while speech recognition systems rely on perception to understand spoken words.
There are different types of perception in AI, each associated with specific sensory input:
- Visual perception – Used in computer vision systems to interpret images, videos, and visual data.
- Auditory perception – Used in speech recognition and natural language processing to interpret spoken language and sounds.
- Tactile perception – Used in robotics to interpret physical touch and pressure.
- Proprioception – Used in robotics to understand the relative position of the machine’s parts, helping it navigate and move correctly.
Each type of perception allows machines to interpret different kinds of sensory input, enabling them to interact more effectively with their environment.
25. Give some pros and cons of decision trees.
Decision trees are a popular machine learning algorithm used for both classification and regression tasks. They are intuitive and easy to visualize, making them a go-to choice for explaining decisions. One of the biggest advantages of decision trees is their interpretability; the decisions made by the model can be easily understood by tracing the tree from the root to the leaf nodes. Additionally, decision trees can handle both categorical and numerical data and are less affected by data scaling and normalization, which simplifies preprocessing.
However, decision trees come with some downsides. They are prone to overfitting, especially if the tree is too deep, meaning they may perform well on training data but poorly on unseen data. Techniques like pruning can mitigate this, but overfitting remains a challenge. Another disadvantage is that decision trees are sensitive to noise in the data. Small variations in the data can lead to a completely different tree structure. Ensemble methods like Random Forests or Gradient Boosted Trees are often used to overcome these limitations, combining multiple decision trees to improve accuracy and robustness.
26. Explain marginalization process.
Marginalization in machine learning and statistics refers to the process of summing or integrating over a set of variables to eliminate them from a probability distribution. This technique is often used in Bayesian inference to make predictions by taking into account all possible values of certain variables, rather than relying on just a single estimate. For example, if you want to predict the outcome of an event, but one of the variables is unknown or unobserved, you can marginalize over that variable to get a more accurate prediction by considering all its possible values.
Marginalization plays a crucial role in probabilistic models, especially in complex models like Hidden Markov Models (HMMs) or Bayesian Networks, where several hidden variables influence the outcome. By marginalizing over the hidden variables, you compute the overall probability of an observed event without needing explicit knowledge of each hidden variable’s value.
In mathematical terms, marginalization is expressed as:
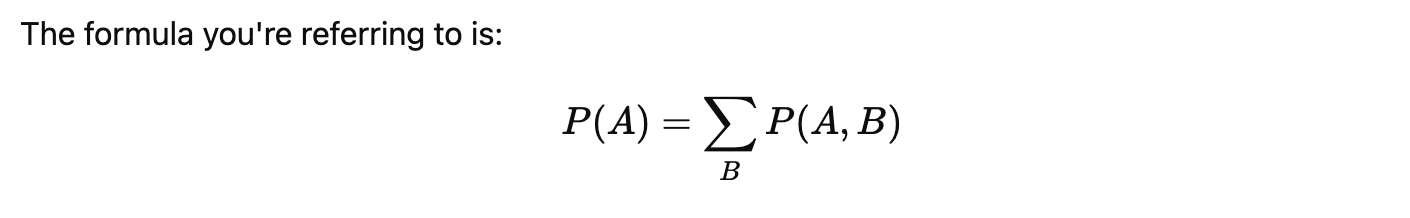
This equation shows how you sum over all possible values of B to obtain the marginal probability of A. It helps reduce the complexity of the model and provides a more generalized understanding of the system under consideration.
27. What is the function of an artificial neural network?
An artificial neural network (ANN) is a computational model designed to simulate the way the human brain processes information. The primary function of an ANN is to learn from data and make predictions or classifications based on patterns it has recognized. Each neural network consists of layers of neurons (nodes), where each neuron receives input, processes it using a set of weights, and passes the output to the next layer. This process mimics the biological neurons in the brain, where information is processed and passed on to other neurons.
The learning process in an ANN is driven by adjusting the weights and biases in each neuron based on the error in the model’s predictions. The backpropagation algorithm is typically used to adjust these weights to minimize the error (or loss function) during training. The more hidden layers the network has, the better it can capture complex patterns in the data. This is why deep learning models, which use deep neural networks with many hidden layers, are so effective at tasks like image recognition and language translation. Neural networks are highly versatile and can be applied to a wide range of tasks, from regression and classification to more complex problems like reinforcement learning.
28. Explain cognitive computing and its types?
Cognitive computing refers to a subset of AI that aims to simulate human thought processes in a computerized model. It uses machine learning, natural language processing (NLP), and other AI techniques to process vast amounts of unstructured data and provide insights or assist in decision-making. Cognitive computing systems, such as IBM Watson, mimic human cognition to some extent, allowing them to understand natural language, learn from experiences, and make recommendations based on data-driven insights. These systems are particularly useful in industries like healthcare, finance, and customer support, where they assist humans in making more informed decisions.
There are various types of cognitive computing systems, including:
- Expert Systems – Designed to replicate the decision-making abilities of a human expert, these systems use rule-based reasoning to solve problems in specific domains (e.g., medical diagnosis).
- Natural Language Processing Systems – These systems understand and generate human language, helping with tasks like sentiment analysis, text summarization, and chatbots.
- Neural Networks – Mimicking the human brain, neural networks are used in cognitive computing for pattern recognition, decision-making, and predictive analytics.
- Reinforcement Learning Systems – These systems learn by interacting with their environment and receiving feedback in the form of rewards or penalties, much like how humans learn through trial and error.
Cognitive computing enhances human capabilities, providing assistance in complex tasks by processing vast datasets, identifying trends, and predicting outcomes.
29. Explain the function of deep learning frameworks.
Deep learning frameworks provide developers with tools to design, train, and evaluate deep neural networks. These frameworks abstract much of the complexity involved in implementing deep learning models, offering pre-built modules for layers, activation functions, optimizers, and loss functions. Popular frameworks like TensorFlow, Keras, PyTorch, and MXNet allow users to create complex deep learning architectures with minimal coding. By using these frameworks, developers can focus on model architecture and experimentation without worrying about the underlying implementation details like backpropagation or gradient descent.
One of the key functions of these frameworks is to optimize the use of computational resources. For instance, they allow models to be run on GPUs or TPUs, significantly speeding up the training process. In addition, deep learning frameworks provide comprehensive tools for monitoring training progress, visualizing model performance using tools like TensorBoard, and fine-tuning hyperparameters. These frameworks also make it easy to deploy trained models into production environments, whether it’s a web app, mobile app, or cloud service.
30. How are speech recognition and video recognition different?
Speech recognition and video recognition are both AI-driven technologies but differ in the type of input data they process and the underlying techniques used. Speech recognition involves converting spoken language into text, and it relies heavily on natural language processing (NLP) and acoustic models to identify and transcribe words accurately. Techniques such as Hidden Markov Models (HMMs) and deep learning algorithms, particularly recurrent neural networks (RNNs) and transformers, are used to model the sequential nature of speech data and handle various accents, pronunciations, and noise.
On the other hand, video recognition focuses on analyzing video data to detect and classify objects, actions, or events. This process involves both computer vision techniques and deep learning algorithms like convolutional neural networks (CNNs). Video recognition tasks include identifying objects, detecting movement, and recognizing human activities. Unlike speech recognition, which processes audio signals, video recognition deals with image sequences and often requires frame-by-frame analysis. Additionally, temporal information plays a significant role in video recognition, as the system needs to analyze not just the static image but also how objects or events change over time in a video.

