Core AI interview questions
Table Of Contents
- Explain Briefly the K-Means Clustering and How Can We Find the Best Value of K?
- Explain Support Vector Machine (SVM).
- Compare Pearson and Spearman Coefficients.
- What is the Difference Between L1 and L2 Regularization?
- What are Some Differences Between a CNN and a FCNN? Layers and Activation Functions? Why are They Structured Differently?
- Explain the Concept of Transfer Learning in Deep Learning.
- What are the Differences Between a Decision Tree and Random Forest?
- What is Overfitting? What are Some Ways to Mitigate It?
- Given an Array, Find All the Duplicates in This Array for Example: Input: [1,2,3,1,3,6,5] Output: [1,3].
- Define Tuples and Lists in Python What are the Major Differences Between Them?
- What are Some Applications of RL Beyond Gaming and Self-driving Cars?
In the dynamic and rapidly growing field of Core AI interview questions typically explore essential concepts and practical applications. Candidates can expect to face inquiries about algorithms, machine learning techniques, neural networks, and data processing. Interviewers often present real-world scenarios to assess how applicants tackle complex problems and innovate solutions. With the average salary for professionals specializing in Core AI integration ranging from $90,000 to $140,000 annually, depending on experience and location, there is significant demand for skilled experts in this area.
This guide is designed to help you prepare effectively for your upcoming Core AI interviews. By exploring a range of essential questions and answers, you’ll gain valuable insights into what employers are looking for in candidates. Topics will include machine learning models, natural language processing, and ethical considerations in AI. With this knowledge, you can enhance your confidence and ability to articulate your understanding during interviews, positioning yourself as a strong contender in the competitive Core AI job market.
Curious about AI and how it can transform your career? Join our free demo at CRS Info Solutions and connect with our expert instructors to learn more about our AI online course. We emphasize real-time project-based learning, daily notes, and interview questions to ensure you gain practical experience. Enroll today for your free demo and embark on your path to becoming an AI professional!
1. Explain Briefly the K-Means Clustering and How Can We Find the Best Value of K?
K-Means clustering is a popular unsupervised learning algorithm used to group similar data points into clusters. The algorithm works by initializing a predefined number of centroids (K) and iteratively assigning data points to the nearest centroid based on a distance metric, typically Euclidean distance. Once all points are assigned, the algorithm recalculates the centroids by averaging the positions of the points in each cluster. This process repeats until the centroids stabilize, meaning they no longer change significantly or a set number of iterations is reached. K-Means is widely used due to its simplicity and efficiency in handling large datasets.
Finding the best value of K is crucial to the performance of the K-Means algorithm. One common method is the Elbow Method, where I plot the sum of squared distances between data points and their corresponding centroids for different values of K.
Here’s a simple Python code snippet to illustrate the Elbow Method:
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
# Sample data
X = [[1, 2], [1, 4], [1, 0], [4, 2], [4, 4], [4, 0]]
# Calculate KMeans for different values of K
wcss = []
for k in range(1, 10):
kmeans = KMeans(n_clusters=k)
kmeans.fit(X)
wcss.append(kmeans.inertia_)
# Plotting the Elbow curve
plt.plot(range(1, 10), wcss)
plt.title('Elbow Method')
plt.xlabel('Number of clusters (K)')
plt.ylabel('WCSS')
plt.show()As K increases, the sum of squared distances decreases. However, after a certain point, the decrease becomes less significant, forming an “elbow” shape on the graph. The point where this elbow occurs is often considered the optimal value of K. Another technique is the Silhouette Score, which measures how similar a point is to its own cluster compared to other clusters. A higher Silhouette Score indicates a better-defined cluster structure, helping to determine the ideal number of clusters.
See also: Artificial Intelligence interview questions and answers
2. Explain Pearson’s Correlation Coefficient.
Pearson’s Correlation Coefficient, often denoted as r, quantifies the linear relationship between two continuous variables. Its value ranges from -1 to +1, where -1 indicates a perfect negative linear correlation, +1 indicates a perfect positive linear correlation, and 0 signifies no correlation. I calculate this coefficient using the formula:
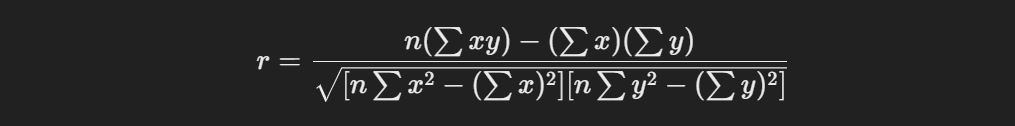
This formula helps me determine how closely two variables move in relation to each other. For example, a high positive value of r indicates that as one variable increases, the other variable also tends to increase, while a high negative value shows that as one variable increases, the other tends to decrease.
While Pearson’s correlation provides valuable insights, it is essential to note that it only measures linear relationships. If the relationship between the variables is nonlinear, the Pearson coefficient may be misleading. Therefore, I complement it with visualizations such as scatter plots to better understand the relationship and consider other correlation measures like Spearman’s rank correlation for non-linear associations.
Here’s a quick example of how to compute Pearson’s correlation in Python:
import numpy as np
from scipy.stats import pearsonr
# Sample data
x = np.array([1, 2, 3, 4, 5])
y = np.array([2, 4, 5, 4, 5])
# Calculate Pearson correlation
corr, _ = pearsonr(x, y)
print(f'Pearson correlation coefficient: {corr:.3f}')See also: Beginner AI Interview Questions and Answers
3. What are the Differences and Similarities Between Gradient Boosting and Random Forest?
Gradient Boosting and Random Forest are both ensemble learning techniques used for regression and classification tasks, but they differ significantly in their approaches. Random Forest operates by constructing multiple decision trees during training and outputting the mode of their predictions (for classification) or the average (for regression). It randomly selects subsets of features for each tree, reducing the risk of overfitting and improving generalization. In contrast, Gradient Boosting builds trees sequentially, where each new tree corrects errors made by the previous ones. This approach focuses on reducing the loss function through gradient descent, making Gradient Boosting often more accurate than Random Forest but also more prone to overfitting if not properly tuned.
Despite these differences, both methods share some similarities. They both aim to improve model accuracy by aggregating predictions from multiple trees and can handle a mix of feature types, including categorical and continuous variables. Additionally, both methods rely on decision trees as their base learners, allowing them to capture complex relationships in the data. When selecting between the two, I consider the specific problem at hand, the nature of the data, and the need for interpretability.
4. What are the Advantages and Disadvantages of Each When Compared to Each Other?
Random Forests have several advantages, such as robustness to overfitting due to averaging predictions from multiple trees, which leads to better generalization. They also offer ease of use, performing well with default parameters, and provide feature importance insights, helping me identify significant variables. However, they can be complex and less interpretable, making it challenging to explain results, and they may require significant computational resources due to the training of numerous trees.
On the other hand, Gradient Boosting often achieves higher predictive accuracy by sequentially correcting errors made by previous trees and can be tailored to optimize various loss functions for different tasks. Its flexibility makes it adaptable to various problems. However, it is prone to overfitting, requiring careful tuning of hyperparameters, and typically has longer training times because trees are built sequentially. Additionally, it can be more sensitive to noisy data, which may impact generalization. Choosing between these two methods depends on my project’s specific needs regarding accuracy, interpretability, and computational resources.
See also: AI Interview Questions and Answers for 5 Year Experience
5. Define Correlation.
Correlation is a statistical measure that describes the strength and direction of a relationship between two variables. I often use it to understand how changes in one variable relate to changes in another, providing insights into their association. The most common correlation measures include Pearson’s correlation coefficient for linear relationships and Spearman’s rank correlation coefficient for non-linear relationships. A correlation can be positive, negative, or zero. A positive correlation means that as one variable increases, the other also tends to increase, while a negative correlation indicates that as one variable increases, the other tends to decrease. Zero correlation means there is no discernible relationship between the two variables.
Understanding correlation is vital in various fields, such as economics, social sciences, and healthcare, as it allows me to identify trends and make predictions based on the relationships between variables. However, it’s essential to note that correlation does not imply causation. Just because two variables are correlated does not mean that one causes the other. For example, a high correlation between ice cream sales and drowning incidents does not imply that one causes the other; rather, both may be influenced by a third factor, such as warm weather.
6. Mention Three Ways to Make Your Model Robust to Outliers.
When building predictive models, outliers can significantly affect the performance and accuracy of the results. To make my models robust to outliers, I typically implement several strategies:
- Use Robust Statistical Measures: Instead of relying on the mean and standard deviation, I opt for median and interquartile range (IQR) to summarize data. This reduces the influence of outliers on central tendency and dispersion.
- Apply Robust Models: I often use models less sensitive to outliers, such as Tree-based models (like Random Forest) and Support Vector Machines with appropriate kernels. These models can handle outliers more effectively than traditional linear models.
- Outlier Detection and Treatment: I apply methods like Z-score analysis or the IQR method to identify outliers. Once detected, I can choose to remove them, transform them, or impute their values based on other data points to mitigate their impact on the model.
Here’s a quick example of how to identify outliers using the Z-score method in Python:
import numpy as np
# Sample data
data = np.array([10, 12, 12, 13, 12, 11, 10, 10, 120]) # 120 is an outlier
# Calculate Z-scores
z_scores = (data - np.mean(data)) / np.std(data)
# Identify outliers
outliers = data[np.abs(z_scores) > 2]
print(f'Outliers detected: {outliers}')By incorporating these approaches, I can improve the robustness of my models and ensure they generalize well to unseen data.
7. Explain Support Vector Machine (SVM).
Support Vector Machine (SVM) is a powerful supervised learning algorithm used for classification and regression tasks. The core idea behind SVM is to find the optimal hyperplane that separates different classes in the feature space. This hyperplane maximizes the margin between the closest points of each class, known as support vectors. By focusing on these support vectors, SVM effectively generalizes to unseen data while being less sensitive to noise in the dataset.
SVM can also handle non-linear relationships using the kernel trick, which transforms the original feature space into a higher-dimensional space where a linear separator can be found. Commonly used kernels include linear, polynomial, and radial basis function (RBF). By selecting the appropriate kernel, I can model complex decision boundaries.
Here’s a simple Python example of how to implement SVM using the Scikit-learn library:
from sklearn import datasets
from sklearn import svm
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# Load dataset
iris = datasets.load_iris()
X = iris.data
y = iris.target
# Split data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Create and train the SVM model
model = svm.SVC(kernel='linear')
model.fit(X_train, y_train)
# Make predictions
y_pred = model.predict(X_test)
# Calculate accuracy
accuracy = accuracy_score(y_test, y_pred)
print(f'Accuracy: {accuracy:.2f}')In this example, I trained an SVM model on the Iris dataset using a linear kernel. The model’s ability to classify data points effectively highlights the strength of SVM in handling both linear and non-linear relationships.
See also: Artificial Intelligence Scenario Based Interview Questions
8. Compare Pearson and Spearman Coefficients.
Pearson and Spearman correlation coefficients are both measures of association between two variables but differ significantly in their application and interpretation. Pearson’s correlation assesses the linear relationship between two continuous variables, assuming that both variables are normally distributed. It provides a single value ranging from -1 to +1, indicating the strength and direction of the relationship. A Pearson correlation of 0 suggests no linear relationship, while values closer to -1 or +1 indicate strong negative or positive relationships, respectively.
In contrast, Spearman’s rank correlation evaluates the monotonic relationship between two variables, making it more suitable for non-linear associations and ordinal data. Unlike Pearson’s coefficient, Spearman does not assume normality and can handle outliers better, as it ranks the data before calculation. This property makes it particularly useful when dealing with non-parametric data or when I suspect that the relationship is not strictly linear. Here’s a quick comparison table:
| Feature | Pearson | Spearman |
|---|---|---|
| Type of relationship | Linear | Monotonic |
| Data type | Continuous, normally distributed | Ordinal or continuous |
| Sensitivity to outliers | Sensitive | Less sensitive |
| Calculation | Based on raw values | Based on ranks |
9. Describe the Motivation Behind Random Forests and Mention Two Reasons Why They are Better Than Individual Decision Trees.
The motivation behind Random Forests stems from the limitations of individual decision trees, which can be prone to overfitting and may fail to generalize well to unseen data. Individual decision trees make predictions based on a series of binary decisions, which can lead to highly complex and sensitive models that capture noise instead of the underlying data patterns. Random Forests, however, address this issue by creating an ensemble of decision trees trained on different subsets of the data and features. This approach enhances predictive accuracy and robustness while significantly reducing overfitting.
Two primary reasons why Random Forests outperform individual decision trees are reduced overfitting and improved accuracy. By combining the predictions from multiple trees, Random Forests minimize the risk of overfitting to the noise in the training data. Additionally, because they use randomness in selecting subsets of features and data points, they capture more diverse patterns in the data, leading to more accurate predictions. This characteristic makes Random Forests a popular choice in many real-world applications where predictive performance is critical.
See also: NLP Interview Questions
10. What are the Bias and Variance in a Machine Learning Model and Explain the Bias-Variance Trade-off?
In machine learning, bias refers to the error introduced by approximating a real-world problem, which may be complex, using a simplified model. High bias often leads to underfitting, where the model fails to capture the underlying patterns in the data. On the other hand, variance refers to the model’s sensitivity to fluctuations in the training data. A model with high variance pays too much attention to the noise in the training data, leading to overfitting and poor generalization to new data points.
The bias-variance trade-off is a critical concept in machine learning that describes the balance between bias and variance to minimize overall error. As I increase the complexity of my model to reduce bias, variance typically increases. Conversely, simplifying the model reduces variance but increases bias. The goal is to find the optimal level of complexity where both bias and variance are minimized, leading to the best performance on unseen data. Understanding this trade-off helps me select the right algorithms and tuning parameters to achieve a well-generalized model.
11. Define the Cross-validation Process and the Motivation Behind Using It?
Cross-validation is a statistical method used to evaluate the performance of a machine learning model by partitioning the original dataset into complementary subsets. In this process, I divide the data into kkk subsets (or folds). For each iteration, I use k−1k-1k−1 folds for training and the remaining fold for testing. This procedure is repeated kkk times, with each fold serving as the test set once. The results are then averaged to provide a more robust estimate of the model’s performance.
The main motivation behind using cross-validation is to ensure that my model generalizes well to unseen data. By utilizing different subsets for training and testing, I can minimize the risk of overfitting and obtain a better understanding of how the model performs on various data points. Cross-validation helps in selecting the best model and tuning hyperparameters effectively, making it an essential step in the machine learning workflow.
While there isn’t a specific code snippet for the cross-validation process itself, here’s how I can implement it using scikit-learn in Python:
from sklearn.model_selection import cross_val_score
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_iris
# Load dataset
data = load_iris()
X, y = data.data, data.target
# Initialize model
model = RandomForestClassifier()
# Perform cross-validation
scores = cross_val_score(model, X, y, cv=5) # 5-fold cross-validation
print("Cross-validation scores:", scores)
print("Average score:", scores.mean())This code snippet demonstrates how to perform cross-validation using the Random Forest model on the Iris dataset. The average score gives an estimate of the model’s performance.
12. Explain What is Information Gain and Entropy in the Context of Decision Trees?
In the context of decision trees, entropy is a measure of the impurity or disorder of a dataset. It quantifies the amount of uncertainty in predicting the class of an instance. The formula for entropy H is given by:
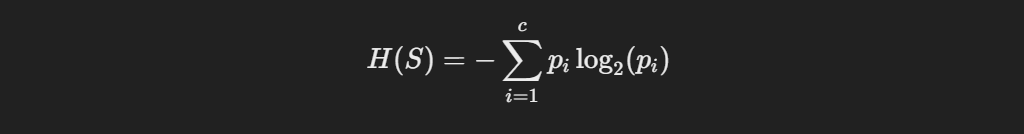
where pi is the probability of class iii in the dataset SSS. A dataset with a uniform distribution among classes has high entropy, indicating high uncertainty, while a dataset with all instances belonging to a single class has low entropy.
Information Gain is derived from entropy and measures the reduction in uncertainty achieved by partitioning the dataset based on a specific attribute. It is calculated as the difference between the entropy of the original dataset and the weighted entropies of the subsets created by the split. The attribute with the highest information gain is selected for the decision node in the tree. This approach ensures that the model captures the most informative features for making predictions.
See also: Intermediate AI Interview Questions and Answers
13. What is the Difference Between L1 and L2 Regularization?
L1 and L2 regularization are techniques used to prevent overfitting in machine learning models by adding a penalty to the loss function. L1 regularization, also known as Lasso regression, adds the absolute value of the coefficients as a penalty term:
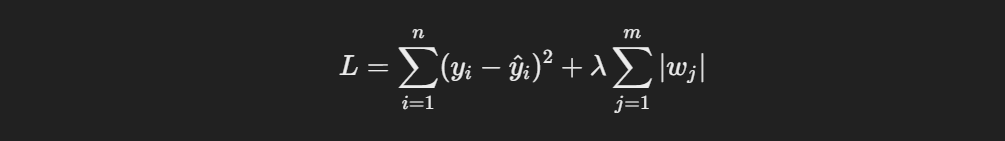
where λ is the regularization parameter. L1 regularization can lead to sparse solutions, meaning it may reduce some coefficients to zero, effectively selecting a simpler model by performing feature selection.
L2 regularization, or Ridge regression, adds the squared values of the coefficients as a penalty term:
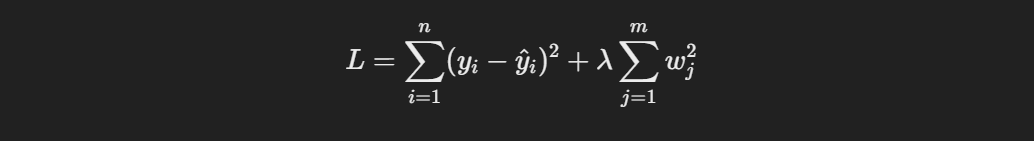
This approach keeps all the features but shrinks their coefficients, distributing the weights more evenly across them. L2 regularization helps in dealing with multicollinearity and is generally preferred when I want to retain all features in the model while controlling their influence.
14. What are Some Differences Between a CNN and a FCNN? Layers and Activation Functions? Why are They Structured Differently?
Convolutional Neural Networks (CNNs) and Fully Connected Neural Networks (FCNNs) differ significantly in their structure and applications. A CNN typically includes convolutional layers, pooling layers, and fully connected layers. The convolutional layers apply filters to the input data, which helps in extracting local features such as edges or textures. Pooling layers reduce the spatial dimensions, maintaining the most critical information while reducing computation. In contrast, an FCNN consists solely of fully connected layers, where every neuron is connected to every neuron in the previous layer, which can lead to a more significant number of parameters.
The activation functions used in CNNs often include ReLU (Rectified Linear Unit) for the convolutional layers, promoting sparsity and mitigating the vanishing gradient problem. FCNNs may use activation functions like sigmoid or tanh, but these can suffer from saturation issues. The primary reason for the different structures is that CNNs are designed to handle spatial data, such as images, where local patterns are critical, while FCNNs are better suited for tabular data where every input feature is equally important. While there’s no specific code needed here, here’s a brief overview of how I could implement a simple CNN in TensorFlow/Keras:.
import tensorflow as tf
from tensorflow.keras import layers, models
# Create a simple CNN model
model = models.Sequential([
layers.Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)),
layers.MaxPooling2D((2, 2)),
layers.Conv2D(64, (3, 3), activation='relu'),
layers.MaxPooling2D((2, 2)),
layers.Flatten(),
layers.Dense(64, activation='relu'),
layers.Dense(10, activation='softmax') # Output layer for classification
])
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
print(model.summary())This example shows how to build a simple CNN architecture using Keras with convolutional and pooling layers.
See also: Advanced AI Interview Questions and Answers
15. Explain the Central Limit Theorem and Give Examples of When You Can Use It in a Real-world Problem.
The Central Limit Theorem (CLT) states that the distribution of the sample means approaches a normal distribution as the sample size increases, regardless of the population’s distribution, provided the samples are independent and identically distributed (i.i.d). This theorem is foundational in statistics because it allows me to make inferences about population parameters using sample statistics.
For instance, I can apply the CLT in quality control processes in manufacturing. If I take multiple random samples of product weights, even if the weights are not normally distributed, the distribution of the sample means will be approximately normal if the sample size is sufficiently large. This allows me to use normal distribution techniques to assess the probability of defects or outliers. Similarly, in public health, if I collect data on patient wait times across various clinics, I can analyze the average wait time using the CLT, enabling effective resource allocation based on predicted distributions.
16. Explain the Linear Regression Model and Discuss Its Assumption.
A linear regression model is a statistical method used to model the relationship between a dependent variable and one or more independent variables. It assumes that the relationship between the variables can be expressed as a linear equation of the form:
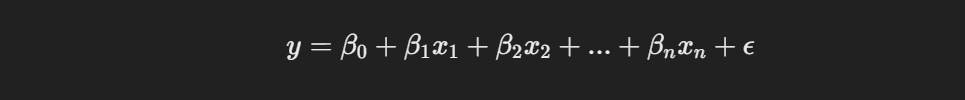
where y is the dependent variable, β0 is the intercept, βi are the coefficients for each independent variable xi and ϵ (epsilon) represents the error term.
The key assumptions of linear regression include linearity, where the relationship between the independent and dependent variables is linear; independence, which means the residuals (errors) should be independent; homoscedasticity, indicating constant variance of residuals across all levels of the independent variables; and normality, where the residuals should be normally distributed. Violating these assumptions can lead to biased estimates and affect the model’s predictive power, so I must check these conditions before relying on linear regression results.
See also: Basic Artificial Intelligence interview questions and answers
17. Mention Three Ways to Handle Missing or Corrupted Data in a Dataset.
Handling missing or corrupted data is crucial for ensuring the quality of my analysis. Here are three common techniques:
- Imputation: I can replace missing values with estimated ones, using methods like mean, median, or mode for numerical data, and the most frequent value for categorical data. More advanced methods include using machine learning algorithms to predict missing values based on other features.
- Deletion: If the proportion of missing data is small, I might choose to remove the affected rows or columns entirely. This method is straightforward but can lead to loss of valuable information, especially if the missingness is systematic.
- Using Algorithms that Support Missing Values: Some machine learning algorithms, such as XGBoost or certain implementations of Random Forest, can handle missing values natively without requiring imputation. This approach allows me to retain the original dataset while still leveraging powerful predictive models.
18. Explain the Kernel Trick in SVM and Why We Use It and How to Choose What Kernel to Use.
The kernel trick in Support Vector Machines (SVM) is a technique that enables the algorithm to work in a higher-dimensional space without explicitly transforming the data. Instead of computing the coordinates of the data in that space, a kernel function computes the inner product of the data points in the transformed feature space. This approach allows SVMs to create non-linear decision boundaries while maintaining computational efficiency.
I use the kernel trick to handle complex datasets where a linear decision boundary is insufficient. Common kernel functions include the linear kernel, polynomial kernel, and radial basis function (RBF) kernel. The choice of kernel depends on the problem at hand: I typically use the linear kernel for linearly separable data, the polynomial kernel for problems where interactions between features are essential, and the RBF kernel for more complex boundaries. It’s crucial to experiment with different kernels and validate their performance using cross-validation techniques to identify the best fit for my dataset.
19. What is the Vanishing Gradient Problem and How Do You Fix It?
The vanishing gradient problem occurs during the training of deep neural networks when gradients of the loss function approach zero as they are propagated back through the layers. This issue can hinder the learning process, particularly in earlier layers, making it difficult for the model to adjust weights effectively and learn complex patterns. The problem is prevalent in networks using activation functions like sigmoid or tanh, which can squash gradients, leading to very small values.
To address the vanishing gradient problem, I can employ several strategies. One effective approach is to use activation functions like ReLU (Rectified Linear Unit), which do not saturate for positive values, allowing gradients to propagate more effectively. Additionally, I can implement techniques like batch normalization, which normalizes layer inputs, helping maintain a more stable distribution and promoting better gradient flow. Another solution is to use skip connections or Residual Networks (ResNets), which create shortcuts for gradients, enabling deeper architectures without significant degradation in training performance.
See also: Generative AI Interview Questions Part 1
20. Given Two Arrays, Write a Python Function to Return the Intersection of the Two.
Here’s a simple Python function to return the intersection of two arrays:
def intersection(arr1, arr2):
return list(set(arr1) & set(arr2))
X = [1, 5, 9, 0]
Y = [3, 0, 2, 9]
result = intersection(X, Y)
print(result) # Output: [0, 9]In this function, I convert both arrays to sets and use the intersection operator (&) to find common elements. The result is converted back to a list. This approach efficiently handles duplicates and quickly computes the intersection, providing the elements present in both arrays.
21. Briefly Explain the A/B Testing and Its Application? What are Some Common Pitfalls Encountered in A/B Testing?
A/B testing, also known as split testing, is a statistical method where I compare two versions of something to determine which performs better. For example, I might show two groups of users different website designs (A and B) and analyze which design results in higher engagement or conversions. It’s a popular method used in marketing, UI/UX design, and product development to make data-driven decisions.
However, there are common pitfalls in A/B testing. One pitfall is stopping the test too early based on preliminary results, which may lead to inaccurate conclusions. Another is not segmenting the audience properly, which can skew results due to differences in user behavior. Lastly, testing too many variations at once without a sufficient sample size can lead to false positives or negatives.
22. Explain the Concept of Transfer Learning in Deep Learning.
Transfer learning is a technique in deep learning where I take a pre-trained model (usually trained on a large dataset) and adapt it to a new task that might have less data. The main idea is that the model has already learned useful features from a different but related problem, so I don’t need to start from scratch. This is particularly useful when dealing with image or language models.
For example, I might use a model like ResNet or BERT, pre-trained on large datasets like ImageNet or Wikipedia, and fine-tune it for a specific task, such as medical image classification or sentiment analysis. By leveraging the knowledge the model has learned, I can achieve higher accuracy with less data and computational resources.
In transfer learning, I might start with a model pre-trained on a large dataset and fine-tune it on a specific task. For instance, I can use a pre-trained image classification model like ResNet and fine-tune it for medical image classification with limited data.
Example:
from tensorflow.keras.applications import ResNet50
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Dense
# Load pre-trained ResNet50 model, excluding the top layer
base_model = ResNet50(weights='imagenet', include_top=False, input_shape=(224, 224, 3))
# Add a new fully connected layer for fine-tuning
x = base_model.output
x = Dense(1024, activation='relu')(x)
predictions = Dense(1, activation='sigmoid')(x)
model = Model(inputs=base_model.input, outputs=predictions)
# Freeze all layers except the last two
for layer in base_model.layers:
layer.trainable = False
# Compile the model
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])Here, I use the pre-trained ResNet50 model and add my custom classification layers.
See also: Generative AI Interview Questions Part 2
23. Describe Briefly the Hypothesis Testing and P-value in Layman’s Terms? Give a Practical Application for Them.
Hypothesis testing is a way to check if the assumptions we have about a dataset are true. Imagine I want to test if a new marketing campaign is more effective than the old one. I’ll create a null hypothesis, which states there’s no difference between the two campaigns, and an alternative hypothesis, which states that the new campaign is better.
The p-value helps me decide whether to reject the null hypothesis. If the p-value is low (typically less than 0.05), I can say with confidence that the new campaign is better. In practical terms, hypothesis testing can be used in A/B testing or quality control, where I want to check if changes lead to significant improvements.
24. Explain Spearman’s Correlation Coefficient.
Spearman’s correlation coefficient is a non-parametric measure of the relationship between two variables. Unlike Pearson’s correlation, which measures linear relationships, Spearman’s correlation assesses how well the relationship between two variables can be described using a monotonic function. This means that if one variable increases, the other does as well, but not necessarily at a constant rate.
In practice, I use Spearman’s correlation when the data is ordinal or when I’m unsure if the relationship is linear. It’s particularly useful in cases where outliers may distort Pearson’s correlation or when the data doesn’t meet normality assumptions.
See also: Machine Learning in AI Interview Questions
25. What is an Activation Function and Discuss the Use of an Activation Function? Explain Three Different Types of Activation Functions.
An activation function in a neural network helps determine whether a neuron should be activated or not, adding non-linearity to the network. This non-linearity allows the model to capture complex patterns in the data. Without activation functions, the neural network would essentially behave like a linear regression model, limiting its ability to solve more complex tasks.
Three common activation functions are:
- ReLU (Rectified Linear Unit): It outputs the input directly if positive, and zero otherwise. It’s widely used due to its simplicity and efficiency.
- Sigmoid: This activation function maps inputs to values between 0 and 1, useful for binary classification problems.
- Tanh: Similar to sigmoid but outputs values between -1 and 1, making it more suitable for handling negative inputs.
26. Explain Bagging Method in Ensemble Learning.
Bagging (Bootstrap Aggregating) is a method in ensemble learning where I create multiple subsets of the training data by sampling with replacement. I then train a separate model on each subset and combine the results (often through averaging for regression or majority voting for classification) to get the final prediction. The main benefit of bagging is that it reduces variance, making the model more robust to overfitting.
Bagging reduces variance by averaging predictions from multiple models. In a Random Forest, multiple decision trees are built on random subsets of data and features, reducing the risk of overfitting.
Example:
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
# Load dataset and split into training and testing
data = load_iris()
X_train, X_test, y_train, y_test = train_test_split(data.data, data.target, test_size=0.2, random_state=42)
# Train a Random Forest model
model = RandomForestClassifier(n_estimators=100, random_state=42)
model.fit(X_train, y_train)
# Predict and evaluate
accuracy = model.score(X_test, y_test)
print("Random Forest accuracy:", accuracy)Here, I demonstrate how to build a Random Forest classifier using the Iris dataset.
27. What are the Differences Between a Decision Tree and Random Forest?
A decision tree is a model that splits the dataset into smaller subsets based on the most significant features, creating a tree-like structure of decisions. It’s easy to interpret, but it’s prone to overfitting, especially on small datasets.
A Random Forest, on the other hand, is an ensemble of decision trees, where each tree is trained on a different subset of the data and features. The final prediction is made by averaging the outputs (for regression) or by majority voting (for classification). Random forests are more robust and less prone to overfitting compared to individual decision trees.
28. What is Self-attention?
Self-attention is a mechanism used in models like Transformers, where the model assigns different weights to different parts of the input. This allows the model to focus on the most relevant parts of the input when making predictions. For example, in a sentence, self-attention helps the model focus on important words when determining the meaning of the sentence.
Self-attention is particularly important in tasks like language translation and text generation, where the relationships between words are crucial for understanding context.
29. Explain Data Augmentation.
Data augmentation is a technique I use to artificially increase the size of a dataset by creating modified versions of the existing data. In image classification, for example, I can apply transformations such as rotation, flipping, scaling, or adding noise to the original images. This helps the model generalize better by learning from more diverse examples, reducing overfitting.
Data augmentation is especially useful when I have limited training data and need to make the model more robust.
30. Explain Logistic Regression Model and State an Example of When You Have Used It Recently.
Logistic regression is a classification algorithm used to predict the probability of a binary outcome. Unlike linear regression, it uses the sigmoid function to map predicted values to probabilities between 0 and 1. It’s commonly used for binary classification tasks, like determining whether an email is spam or not.
Logistic regression helps me classify binary outcomes. For example, if I want to predict customer purchases (yes/no) based on features like age, income, and browsing behavior, logistic regression is ideal for this.
Example:
from sklearn.linear_model import LogisticRegression
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
# Load dataset
data = load_breast_cancer()
X_train, X_test, y_train, y_test = train_test_split(data.data, data.target, test_size=0.2, random_state=42)
# Train logistic regression model
model = LogisticRegression(max_iter=1000)
model.fit(X_train, y_train)
# Predict and evaluate
accuracy = model.score(X_test, y_test)
print("Logistic Regression accuracy:", accuracy)This example uses logistic regression to classify breast cancer data, predicting whether a tumor is malignant or benign.
31. Explain Gradient Boosting Method in Ensemble Learning?
Gradient Boosting is a popular ensemble technique that builds models sequentially, with each new model correcting the errors of its predecessor. I start by fitting a simple model to the data (e.g., a decision tree) and calculate its residuals, which are the errors. Then, I fit another model to predict these residuals and update the overall prediction by combining the models’ outputs. This process repeats iteratively, and each new model focuses on the mistakes made by the previous ones.
The main benefit of gradient boosting is that it can produce highly accurate models. However, it can also be prone to overfitting if not properly tuned. Common algorithms like XGBoost and LightGBM are implementations of gradient boosting.
32. What is Overfitting? What are Some Ways to Mitigate It?
Overfitting occurs when a machine learning model performs well on the training data but poorly on new, unseen data. This happens because the model captures noise or irrelevant details in the training data, making it less generalizable.
To mitigate overfitting, I use:
- Cross-validation: It ensures that the model is tested on multiple subsets of the data, improving its robustness.
- Regularization: Methods like L1 or L2 regularization add penalties to the model’s complexity.
- Pruning (for decision trees): It removes branches that have little importance in decision tree-based algorithms.
- Dropout (for neural networks): It randomly deactivates some neurons during training to prevent the model from becoming too reliant on certain patterns.
33. Explain Capsule Networks in Deep Learning.
Capsule Networks are a type of neural network designed to address some of the limitations of traditional convolutional neural networks (CNNs), particularly their inability to capture spatial hierarchies effectively. A capsule is a group of neurons that work together to represent a specific feature, along with its spatial orientation.
In a capsule network, instead of pooling layers that reduce information, capsules preserve more detailed information about the position of features in an image. This makes capsule networks better at understanding relationships between parts of an object, like the position of a nose relative to the eyes in a face.
34. Given an Array, Find All the Duplicates in This Array for Example: Input: [1,2,3,1,3,6,5] Output: [1,3].
To find duplicates in an array, I can use a simple algorithm by iterating through the array and checking for repeated elements using a set.
Code Example:
def find_duplicates(arr):
duplicates = []
seen = set()
for num in arr:
if num in seen:
duplicates.append(num)
else:
seen.add(num)
return duplicates
# Test the function
input_arr = [1, 2, 3, 1, 3, 6, 5]
print("Duplicates:", find_duplicates(input_arr))Output: [1, 3]
This function uses a set to keep track of numbers we’ve seen before and appends duplicates to a list.
35. Define Tuples and Lists in Python What are the Major Differences Between Them?
In Python, lists and tuples are both used to store collections of items, but they have key differences. A list is mutable, meaning I can change its elements after creation (e.g., add, remove, or modify items). On the other hand, a tuple is immutable, meaning once I create it, I can’t change it.
Key Differences:
- Mutability: Lists are mutable, tuples are not.
- Syntax: Lists are created using square brackets
[ ], and tuples are created using parentheses( ). - Performance: Tuples are faster to access than lists due to their immutability.
36. What is Active Learning?
Active Learning is a machine learning technique where the model selectively queries the most informative data points from a dataset to learn more efficiently. Instead of training on all available data, the model chooses specific examples where it’s uncertain or likely to gain the most information, allowing it to improve with fewer labeled examples. This is particularly useful when labeling data is expensive or time-consuming.
For instance, in a binary classification task, the model might query examples that are closest to the decision boundary for labeling, as these are likely to provide the most insight.
37. What are Generative Adversarial Networks (GANs)?
Generative Adversarial Networks (GANs) consist of two neural networks—the generator and the discriminator—that are trained together. The generator tries to produce fake data that resembles real data, while the discriminator tries to distinguish between real and fake data. As they compete, both networks improve: the generator gets better at creating realistic data, and the discriminator gets better at spotting fakes.
A common application of GANs is generating realistic images from noise, such as turning rough sketches into detailed images.
38. What is the Independence Assumption for a Naive Bayes Classifier?
The independence assumption in a Naive Bayes classifier means that the features used to make a prediction are assumed to be independent of each other, given the class label. While this assumption is rarely true in real-world data, Naive Bayes still works surprisingly well in many applications, such as text classification, where the occurrence of one word is often independent of the occurrence of another.
39. Why Should We Use Batch Normalization?
Batch normalization is a technique I use to normalize the inputs of each layer in a neural network. By normalizing the inputs, I stabilize the learning process and allow the network to converge faster. Batch normalization also helps mitigate issues like vanishing gradients and reduces the need for careful weight initialization.
In addition, batch normalization adds some regularization, making the network more robust to overfitting.
40. What are Some Applications of RL Beyond Gaming and Self-driving Cars?
Reinforcement learning (RL) is commonly associated with gaming and self-driving cars, but it has many other applications. For instance, RL can be used in:
- Robotics: Teaching robots to perform tasks like grasping objects or navigating complex environments.
- Healthcare: Optimizing treatment plans or managing drug dosages over time.
- Finance: RL can be used to develop trading algorithms or optimize investment portfolios.
- Manufacturing: Improving the efficiency of processes like inventory management or predictive maintenance.
These applications show that RL can be applied to dynamic, real-world problems that involve sequential decision-making.
Conclusion
As I prepare for the Core AI interview questions, I recognize the significance of understanding the fundamental concepts and practical applications of artificial intelligence. The range of topics covered in these questions—from machine learning algorithms to deep learning architectures—highlights the diverse skill set required for a successful career in AI. Gaining a solid grasp of these concepts will not only help me answer interview questions confidently but also enable me to apply this knowledge effectively in real-world scenarios.
Moreover, mastering these core AI topics will position me as a strong candidate in a competitive job market. With the increasing demand for AI professionals, having a deep understanding of essential concepts like gradient boosting, overfitting, and generative adversarial networks will set me apart from other applicants. By focusing on both theoretical knowledge and practical skills, I will be well-prepared to tackle the challenges presented in AI roles and contribute meaningfully to innovative projects within the field.

